
Sedan några dagar tillbaka finns knappt 800 blyertsskisser tecknade av arkitekten Ferdinand Boberg fritt tillgängliga på Wikimedia Commons. Bilderna kommer från Nordiska museets arkiv, dit Boberg donerade arbetsmaterialet för sitt planschverk Svenska bilder.
Knappt 3000 bilder från Nordiska museets samlingar fanns sedan tidigare tillgängliga på Wikimedia Commons, men Bobergbilderna är speciella eftersom de kopierats över direkt från Digitalt museum.
Tillsammans med Wikimedia Sverige har Nordiska museet tagit fram ett skript för den som vill kopiera bilder från Digitalt museum till Wikimedia Commons. Skriptet finns tillgängligt som öppen källkod vilket gör det möjligt för andra museer att använda koden för sina egna samlingar.
Hur går en bildflytt till i praktiken? Det mesta handlar om att förbereda metadata så att bilderna blir så användbara som möjligt. Eftersom Bobergteckningarna importerats till Primus (den samlingsförvaltningsdatabas Nordiska museet använder) från en annan databas behöver informationen ses över. De 785 poster som gåtts igenom lades därför i en egen mapp i Digitalt museum. Därefter kördes fyra olika skript:
DiMuHarvester
DiMuHarvester hämtar metadata för samtliga objekt i mappen med hjälp av Digitalt Museums API. I nuläget hanterar skriptet bara fotografier/bildkonst. Stöd för föremålsbilder (som beskrivs annorlunda) tillkommer nästa år.
DiMuMappingUpdater
DiMuMappingUpdater går igenom den metadata som hämtats och skapar listor med de nyckelord, personer och platser som förekommer. Nordiska museets listor ser ut så här: nyckelord, personer och platser.
Dessa begrepp behöver därefter kopplas till kategorier på Wikimedia Commons samt personer och platser i Wikidata. Begrepp som inte matchas kommer fortfarande att synas på Wikimedia Commons men bara som del av ett fritextfält.
make_NordicMuseum_info
make_NordicMuseum_info tar all metadata från de två första stegen och kombinerar till en ny fil med all information som Wikimedia Commons behöver, inklusive filnamn till själva bildfilerna. Det här skriptet är skräddarsytt för Nordiska museet och behöver alltså anpassas för att andra ska kunna använda det.
uploader
uploader, slutligen, loggar in på Wikimedia Commons och laddar upp en bild i taget med kompletta metadata.
För de museer som tillgängliggör sina samlingar på Digitalt museum är det en relativt liten insats att anpassa skriptet till sina egna förutsättningar. Ta gärna kontakt med mig (Aron Ambrosiani, aron.ambrosiani@nordiskamuseet.se) eller André Costa på Wikimedia Sverige så kan vi reda ut vad som behöver modifieras!
Illustration: Stockholm, Södermalm, Kv. Värmdögatan (Nuvarande Malmgårdsvägen), tecknad av Ferdinand Boberg 1917.
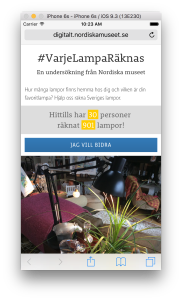 I samband med
I samband med 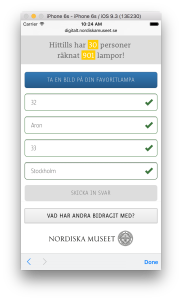 Formuläret består av ett fotofält, ett fält för antal lampor hemma samt demografiska uppgifter (namn, ålder och ort). Om den som laddar upp är minderårig kompletteras formuläret dessutom med ett extra adressfält så att vi kan kontakta målsman vid behov.
Formuläret består av ett fotofält, ett fält för antal lampor hemma samt demografiska uppgifter (namn, ålder och ort). Om den som laddar upp är minderårig kompletteras formuläret dessutom med ett extra adressfält så att vi kan kontakta målsman vid behov.











.Teckning_av_Ferdinand_Boberg_-_Nordiska_museet_-_NMA.0090963.jpg){kind=link}